AI 工程范式的三次跃迁
AI 工程的范式在过去三年里经历了三次跃迁:
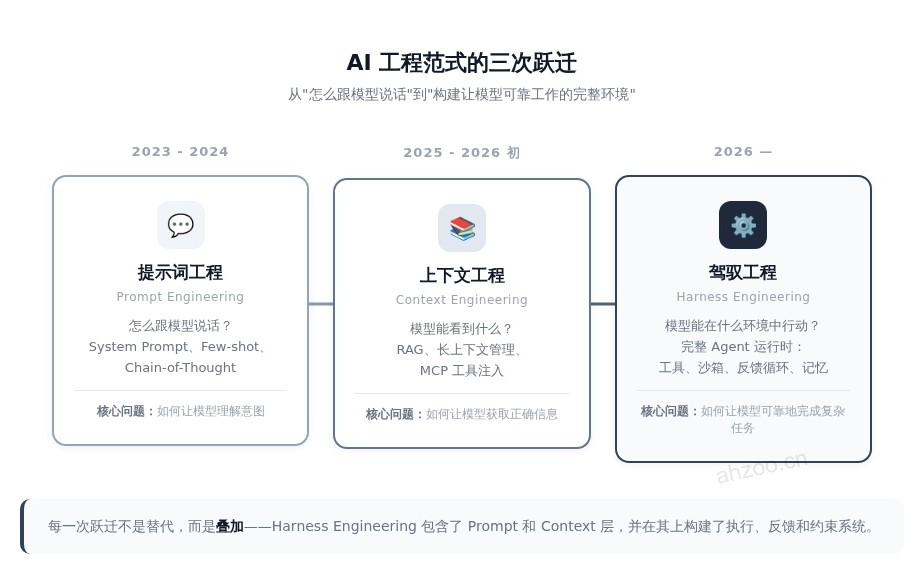
2023-2024:Prompt Engineering——核心问题是「怎么跟模型说话」。System Prompt、Few-shot、Chain-of-Thought,都是为了让模型更好地理解你的意图。
2025-2026 初:Context Engineering——核心问题变成了「模型能看到什么」。RAG、长上下文管理、MCP 工具注入,都是为了让模型获取正确的信息。
2026 至今:Harness Engineering——核心问题升级为「模型能在什么环境中行动」。不再只是让模型"理解"和"知道",而是构建一个完整的运行时环境,让模型能可靠地完成复杂任务。
每一次跃迁不是替代,而是叠加。Harness Engineering 包含了 Prompt 和 Context 层,并在其上构建了执行、反馈和约束系统。
Harness 到底是什么?
这个词在最近的讨论里被用得很模糊,有必要先说清楚。
一个简洁到暴力的公式
Viv Trivedy 提出了一个公式:
Agent = Model + Harness
简单来说就是:你用的 AI 编程助手,等于底层大模型加上围绕它搭建的一切脚手架。
模型是引擎,Harness 是底盘、变速箱、悬挂和整个车身。
Addy Osmani(Google Chrome 团队)把这个观点推到了极致:
"一个还行的模型配上一个优秀的 Harness,完胜一个顶级模型配上一个糟糕的 Harness。"
这不是修辞。在 Terminal Bench 2.0 上,Claude Opus 4.6 在 Claude Code(官方 Harness)中的得分,远低于同一个模型在一个定制 Harness 中的得分。有团队仅仅通过更换 Harness,就把编码 Agent 从 Top 30 拉到了 Top 5。模型没变,变的是 Harness。
Mitchell Hashimoto 的定义
Mitchell Hashimoto 在他 2026 年 2 月的博客里,把自己的 AI 采纳之旅分为六个阶段,第五阶段叫做「Engineer the Harness」。他的定义只有一句话:
“It is the idea that anytime you find an agent makes a mistake, you take the time to engineer a solution such that the agent never makes that mistake again.”
每当你发现 Agent 犯了一个错误,你就花时间去工程化一个解决方案,让它再也不会犯同样的错。
他提到了两类具体做法:
-
在
AGENTS.md里记录 Agent 的坏行为模式,防止重现。他以 Ghostty 项目的AGENTS.md为例,说「那个文件里的每一行,都来自一次真实的坏行为,写进去之后几乎全部得到了解决」。 -
编写专用工具脚本(截图工具、过滤测试等),让 Agent 有办法验证自己的工作是否做对了。
OpenAI 的工程实践
OpenAI 的文章则从另一个角度——组织级工程实践——描述了 Harness。他们的一个团队用 3 名工程师 + Codex 智能体,在 5 个月内交付了 100 万行代码的产品,没有一行代码是人工编写的。
他们的 Harness 包含:
-
文档和设计历史:让 Agent 理解"为什么这样设计"
-
评估 Harness:自动验证 Agent 的输出质量
-
代码审查和响应:Agent 和人类之间的反馈循环
-
管理仓库本身的脚本:让系统自我维护
-
生产环境配置:让 Agent 理解运行时约束
他们还建立了一套「黄金原则」——偏好共享工具包而非手写辅助函数、不 YOLO 式探测数据、在边界处验证数据形状。这些原则被编码进仓库,由定期的后台 Codex 任务扫描偏差并自动开 PR 修复。
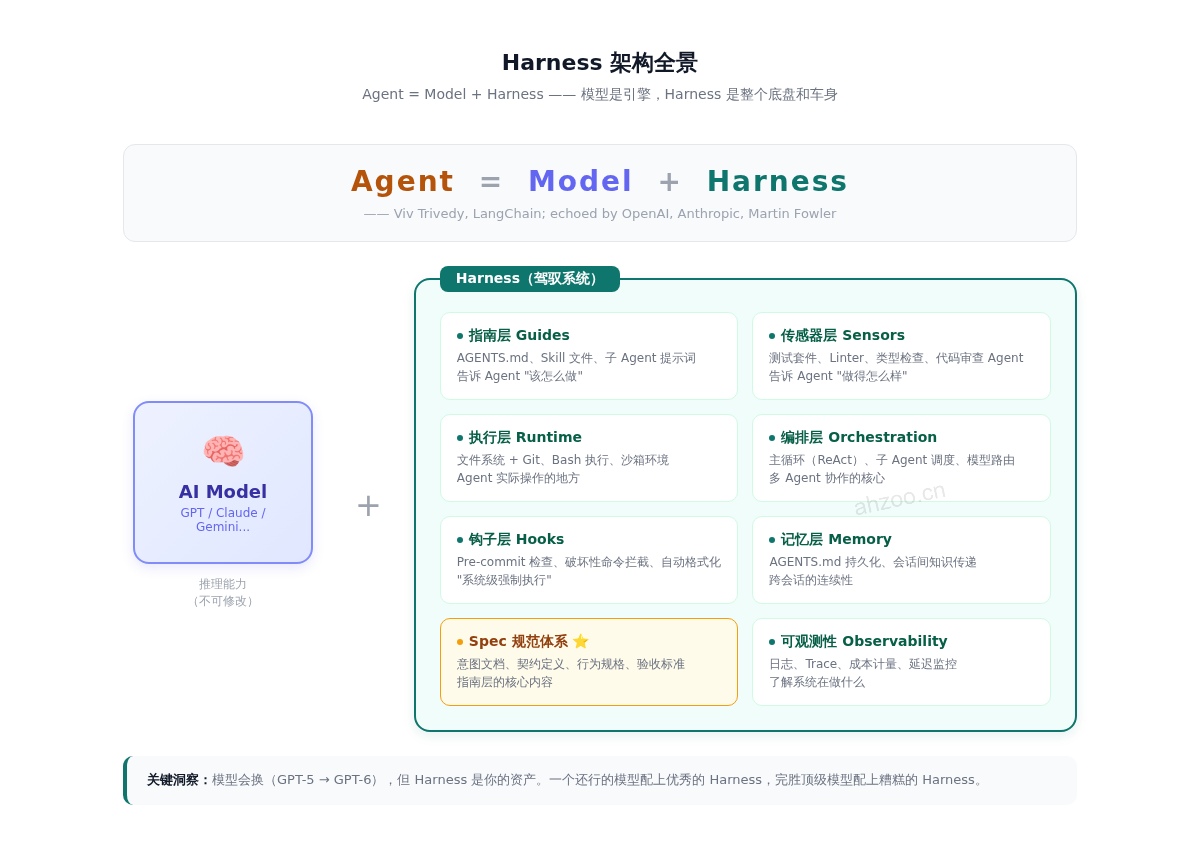
Harness 的完整架构
综合 Mitchell Hashimoto、OpenAI、Martin Fowler 和 Addy Osmani 的实践,一个成熟的 Harness 包含以下层次:

指南层(Guides)——告诉 Agent 该怎么做:
-
AGENTS.md/CLAUDE.md:项目级的行为规范 -
Skill 文件:按需加载的专项能力说明
-
子 Agent 提示词:分工明确的专项 Agent
Martin Fowler 的 Thoughtworks 团队将指南分为两类:
-
计算型指南:Linter 规则、类型检查、自定义静态分析——机器可执行的硬约束
-
推理型指南:代码审查 Agent、架构合规检查——需要模型推理的软约束
传感器层(Sensors)——告诉 Agent 做得怎么样:
-
测试套件:单元测试、集成测试、端到端测试
-
Linter 和静态分析:代码风格、类型安全、依赖方向
-
代码审查 Agent:架构合规性、设计模式检查
执行层(Runtime)——Agent 实际操作的地方:
-
文件系统 + Git:持久化状态和版本控制
-
Bash 执行:通用问题解决能力
-
沙箱环境:隔离、安全、可复现
编排层(Orchestration)——多 Agent 协作的核心:
-
主循环(ReAct):推理 → 行动 → 观察 → 重复
-
子 Agent 调度:专项任务分派
-
模型路由:不同任务用不同模型
钩子层(Hooks)——系统级强制执行:
-
Pre-commit 检查:每次编辑后自动跑 lint 和 typecheck
-
破坏性命令拦截:阻止
rm -rf、git push --force -
自动格式化:不让 Agent 浪费 token 在空白符上
记忆层(Memory)——跨会话的连续性:
-
AGENTS.md持久化:每次会话开始时注入 -
会话间知识传递:从一个 session 到下一个
可观测性(Observability)——了解系统在做什么:
-
日志、Trace、成本计量、延迟监控
SDD 在 Harness 中的三个角色
现在回到核心问题:在这个 Harness 体系里,SDD(Spec-Driven Development)扮演什么角色?
仔细分析 OpenAI 和 Mitchell Hashimoto 的实践,你会发现 Spec 在 Harness 中承担着三个不可替代的角色:
角色 1:意图锚点(Intent Anchor)
Agent 不参与需求讨论,它只执行。Spec 是人类意图的唯一载体——“这个功能要做什么”、“为什么做”、“哪些是必须做的、哪些是可选的”。
没有 Spec,Agent 只能靠猜。猜对了是运气,猜错了就是那个"深色模式把所有图标都反色了"的段子。
OpenAI 的文章里反复强调一个观点:“人们脑子里的东西,系统是看不到的。” Slack 讨论中达成的架构共识?如果没写进仓库,Agent 就不知道,就像一个三个月后才入职的新人一样。
角色 2:约束生效的语义基础(Semantic Foundation)
OpenAI 用 linter 和结构测试来机械地强制执行架构规则——比如层间依赖方向、文件大小限制、命名规范。这些是「格式」层面的约束,可以完全自动化。
但 linter 检查不了语义。 它不知道「某个错误码在跨服务场景下应该怎么处理」,不知道「某个接口字段在特定来源场景下的业务含义」,不知道「这个状态的流转规则是什么」。
这些语义,必须被显式写下来,Agent 才能正确推理。Spec 的契约层和行为规格层承载的,正是这类「linter 管不到、但 Agent 必须知道」的语义约定。
角色 3:反馈循环的校准基准(Calibration Baseline)
测试和 Linter 只能告诉你"代码是否符合规则",Spec 告诉你"代码是否符合意图"。
在 OpenAI 的实践中,他们采用了 Planner → Generator → Evaluator 的三 Agent 架构。Generator 负责写代码,Evaluator 负责检查。Evaluator 检查的依据是什么?就是 Spec。
没有 Spec,Evaluator 只能检查"代码能不能跑"。有了 Spec,Evaluator 可以检查"代码是不是做了正确的事"。这是从"正确性"到"合规性"的质变。
Vibe Coding、SDD、Harness Engineering 的关系
这三者不是非此即彼的选择,而是同一光谱上的不同位置:

Vibe Coding(氛围编程):凭感觉、快、糙。适合原型验证和创意探索。
SDD(规范驱动开发):规格先行、契约驱动。适合需求明确的模块级开发。
Harness Engineering(驾驭工程):构建运行环境,让 AI 自主可靠执行。适合复杂系统的工程化。
它们之间的关系是递进和互补的:
-
Vibe → SDD:当原型验证有效、需求稳定后,用 Spec 固化规则,解决"看起来能用"到"真正能用"的鸿沟。
-
SDD → Harness:当系统复杂到需要多 Agent 协作、持续迭代时,用 Harness 构建自动化环境,让 AI 自主可靠运行。
现实中,大型项目常混合使用——Vibe 做探索、SDD 做模块、Harness 做整体工程化。
“棘轮效应”:Harness 的核心运行机制
理解了 Harness 和 SDD 的关系,再来看一个关键的运行机制——棘轮效应(Ratchet Effect)。

Mitchell Hashimoto 的定义本质上描述的就是一个棘轮:
-
Agent 执行任务
-
出错了
-
工程师分析错误原因
-
在 Harness 中添加约束(写进 AGENTS.md、加 Linter 规则、写测试、加 Hook)
-
同类错误永远不再发生
这个循环有一个关键特性:只紧不松。每次迭代,Harness 都会新增约束来防止已发现的错误再次发生。随着时间推移,Agent 的行为空间被逐步收窄到"正确"的范围内。
Mitchell 以 Ghostty 项目的 AGENTS.md 为例:
“那个文件里的每一行,都来自一次真实的坏行为,写进去之后几乎全部得到了解决。”
OpenAI 团队也有类似的实践。他们发现团队每周要花 20% 的时间清理"AI 垃圾"——Agent 复制了代码库中已有的不优模式。解决方案不是人工清理,而是把"黄金原则"编码进仓库,让后台 Codex 任务定期扫描偏差并自动修复。
技术债像高息贷款——持续小额偿还,远好过一次性痛苦清理。
SDD 会过时吗?
模型会换,Spec 不会
GPT-4 → GPT-5 → GPT-5.5 → Claude Opus 4 → Opus 4.6,甚至最近的Opus 4.7,模型迭代速度极快。但你的业务需求、接口契约、行为规范不会因为换了模型就改变。
Spec 是模型无关的资产。今天用 GPT-5.5 写的 Spec,明天换 Claude Opus 5 一样能用。Harness 中的指南层和传感器层可以复用,只是换了底层的模型。
模型越强,约束越关键
这听起来反直觉,但逻辑很简单:
-
模型弱的时候,它做不了太多事,破坏力有限
-
模型强的时候,它能做的事情多得多,没有约束的破坏力也大得多
OpenAI 的文章里有一句很精辟的话:
“Agent 在有严格边界和可预测结构的环境中最为有效。”
一个能自主写 100 万行代码的 Agent,如果没有 Spec 约束,它也能自主制造 100 万行技术债。
Harness 是放大器,Spec 是被放大的内容
这是最核心的论点。
Harness 的执行能力越强,它对输入质量的要求就越高。就像一个高保真音响系统——输入是噪音,输出就是高保真的噪音。
SDD 提供的正是这个"输入质量"。 Spec 定义了意图、契约和行为规范,Harness 负责高保真地执行。没有 Spec 的 Harness,是一个没有乐谱的乐队——乐器再好,也演奏不出旋律。
一个真实的反面案例
知乎上有一篇广泛传播的文章,标题是《95% 的 Vibe Coding 项目活不过两周》。核心观点:
Vibe Coding 在原型阶段效率惊人,但 90-95% 的 AI 编码项目死于"规模化陷阱"——代码能跑但没人敢改。
原因很简单:没有 Spec,就没有"真相来源"。每次修改都是一次冒险,因为你不知道"正确的行为"应该是什么。
实践建议:从哪里开始?
如果你认同上述分析,想在自己的项目中引入 SDD + Harness,这里有一个务实的起步路径:
第一步:写 AGENTS.md
这是 Harness 中投资回报率最高的单一组件。不需要完美,从记录 Agent 的真实错误开始:
1# AGENTS.md2 3## 项目概述4这是一个电商订单系统,使用 TypeScript + NestJS + PostgreSQL。5 6## 禁止事项7- 不要修改 `src/legacy/` 目录下的任何文件8- 不要使用 `any` 类型9- 不要直接操作数据库,必须通过 Repository 层10 11## 代码规范12- 使用我们的自定义 logger,不要用 console.log13- 所有 API 响应必须遵循 `ApiResponse<T>` 包装格式14- 错误码参考 `src/constants/error-codes.ts`15 记住 Mitchell 的原则:AGENTS.md 里的每一行,都应该来自一次真实的错误。
第二步:建立最小可行的 Spec 体系
不需要 200 页文档。一份好的 Spec 可以是一页 Markdown:
1# Spec: 用户登录2 3## 意图4提供邮箱+密码登录能力,支持多设备同时在线。5 6## 契约7- POST /api/auth/login8- Request: { email: string, password: string }9- Response: { token: string, refreshToken: string, expiresIn: number }10 11## 行为规格12- 密码错误 3 次后锁定账户 15 分钟13- 登录成功后记录设备信息14- token 有效期 2 小时15 16## 验收标准17- [ ] 正确邮箱+密码返回 token18- [ ] 错误密码返回 40119- [ ] 账户锁定返回 42320- [ ] token 在 2 小时后过期21 把它放在仓库里,让 Agent 在开始工作前先读它。
第三步:搭建反馈传感器
至少要有:
-
自动化测试:Agent 写完代码后自动跑
-
类型检查:每次编辑后自动跑
-
一个简单的 pre-commit hook
这些是 Harness 中投资回报率最高的组件。
第四步:启动棘轮
每次 Agent 犯错,问自己:我能不能改 Harness 让这个错误永远不再发生? 如果能,就改。
这就是棘轮——它只会越拧越紧。
写在最后
2026 年的 AI 工程正在经历一个有趣的分化:
一边是 Vibe Coding——跟 AI 聊天,快速出原型,适合探索和实验。
另一边是 Harness Engineering + SDD——构建约束、编码判断、建立反馈循环,适合交付真正要在生产环境运行的系统。
但是它们并不是对立。原型阶段用 Vibe Coding,交付阶段用 Harness + SDD。根据不同的场景选择不同的实现才是较优解。
Harness Engineering 告诉我们:模型的差距是 Harness 的差距。 SDD 告诉我们:没有规格的 AI 编码是自由落体。
把它们结合起来,你得到的是一个有约束、有反馈、可迭代、可维护的 AI 辅助开发系统。这不是回到瀑布流,这是在 AI 时代重新发明工程纪律。
而工程纪律,从来不会因为工具变强而过时。恰恰相反——工具越强大,纪律越重要。